
基于机器视觉 YOLO 目标检测算法的绝缘子及缺陷识别
目标
- 绝缘子及数量识别
- 绝缘子缺陷识别
- OAK-D 人工智能相机实验验证
效果


YOLO 算法理论
研究 YOLO 理论之前需要有一定的深度学习基础,到掌握卷积神经网络的程度就够了,更深入的在学习过程中遇到不懂的再查。
YOLO 理论这里就不详细介绍了,一时半会介绍不完。
YOLOv1-v3 参考原作者 Joseph Redmon 的博客:pjreddie.com,其中有论文的地址,也有 Linux 上的使用示例。
YOLOv4、YOLOv5 和 YOLOX 参考 GitHub :
模型训练过程
首先要准备好 PASCAL-VOC 格式的数据集。
VOC 格式的数据集由图片文件和标签文件组成,标签文件是监督学习中的训练参考标准。
一般开源网站提供的数据集,也提供相应的标签文件,如 飞桨AIStudio。
我的绝缘子数据集采用的是国家电网发布的 CPLID(Chinese Power Line Insulator Dataset)。
这里简单介绍一下如何自己制作标签文件。
首先是你想识别的目标的图片集,越多越好,数量确实少的话可以使用数据增强。
准备好图片集后,去 git clone 一个 labelImg(或者 pip install labelImg),运行软件,然后按照教程对图像进行分类标注,示例:
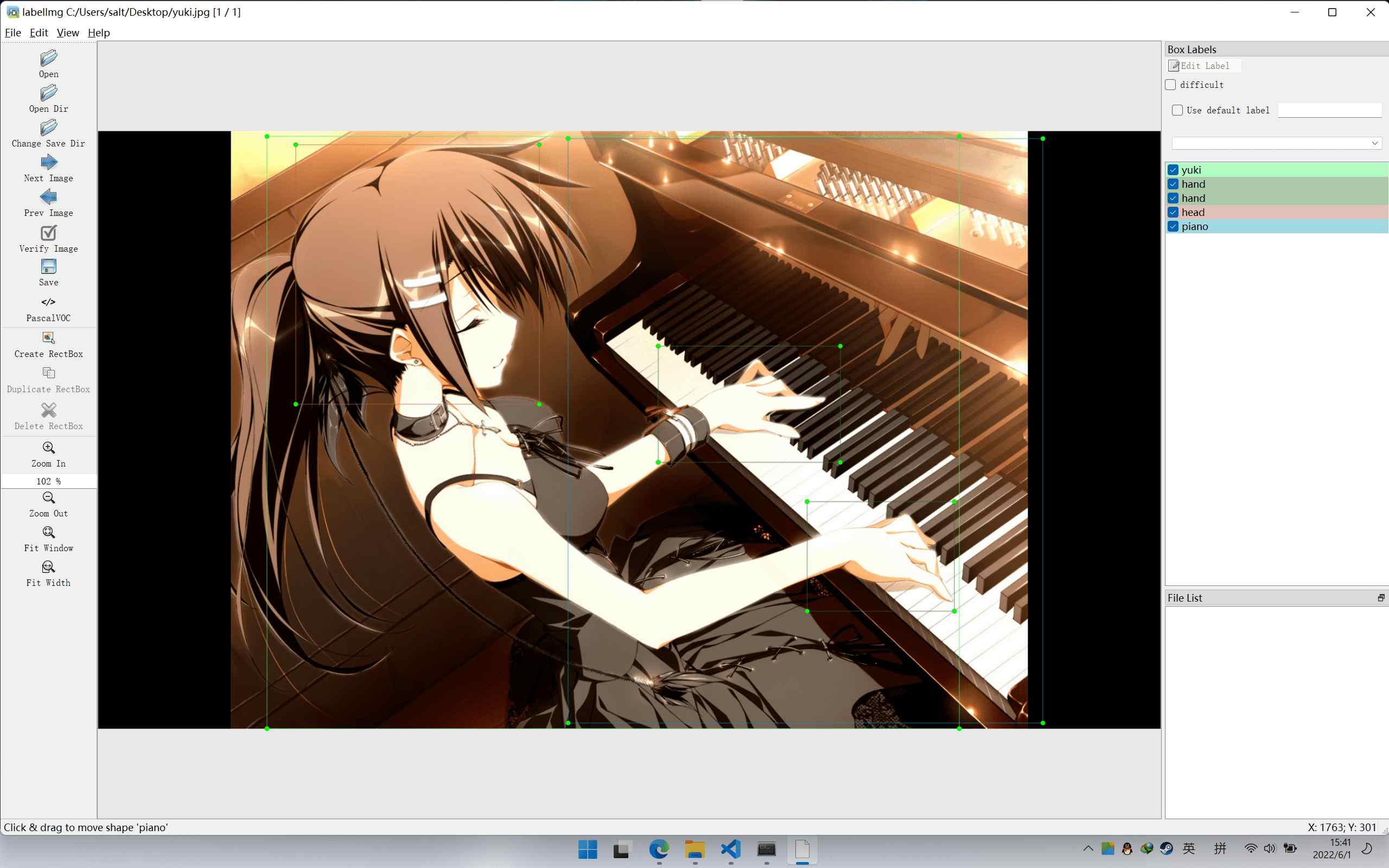
标注完点击保存就会生成相应的 .xml 文件,这就是标签文件了,它和图片文件是同名的。

准备好每一张图片及其对应的标签文件后,数据集就算是准备好了。
准备好数据集后,将其部署到 YOLO 神经网络的输入,训练即可。
我是采用的 Bubbliiiing 搭建的 yolox-pytorch,博客地址:YOLOX_Bubbliiiing_CSDN
这位博主介绍得很详细,按照他的教程一步步来就行。
YOLO 算法理论比较复杂,想弄懂有一定的知识门槛。使用过程却没什么知识门槛,一步步按照教程配置环境、模型,然后训练就行,但却有一定的 硬件 门槛,就我自己的经历举例子:
- 一开始打算用腾讯云的轻量应用服务器(也就是本博客网站部署的地方)来跑,可用起来发现连打开个 PyCharm 都要加载半天,真要训练起来估计至少一个星期。
- 云服务器不行,就拿自己的笔记本电脑来跑,但因为是办公本,显卡也不是英伟达的,不能用 CUDA,所以训练时只能用 CPU,跑一次大概 40 个小时,1 天 2 夜的样子。等 1 天 2 夜到无所谓,但是它训练的时候电脑 CPU 被占满了,啥也干不了,于是这个硬件也淘汰了。
- 期间去阿里云看了看深度学习专用的服务器,发现最便宜的也要一个月 500 元左右,不太划算。于是考虑决定换个新笔电。 弄了个 3060 显卡的拯救者 R9000P。有了 GPU 训练起来可真是快多了,训练一次(iteration)只要 5 个小时左右,睡前开始训练,醒来就训练好了。
训练过程需要关注的是损失函数的变化,一般损失函数收敛,训练就可以停止了,如果不收敛,就适当增加训练的代(epoch)数。
我采用的默认的 300 代,损失函数变化如图(左:绝缘子缺陷 右:绝缘子):
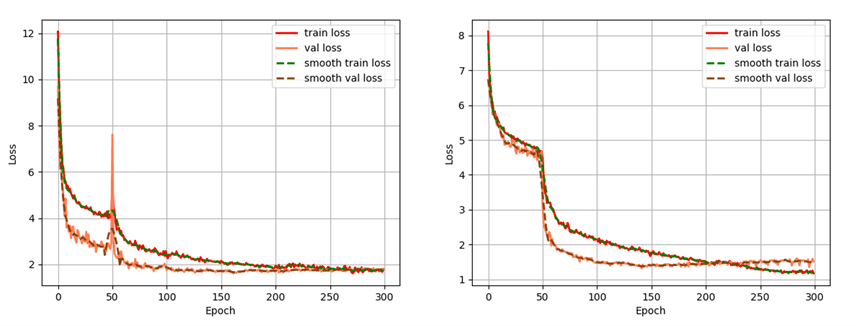
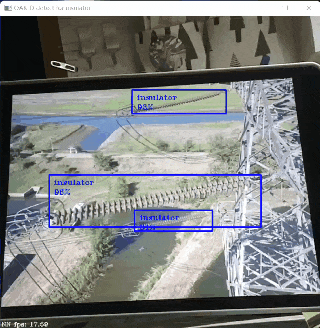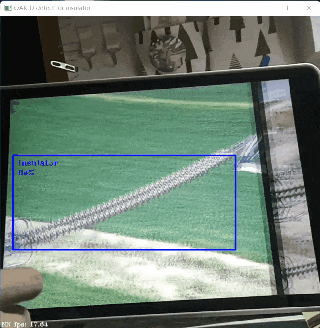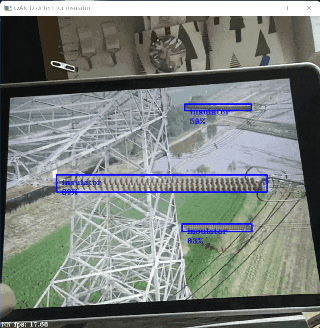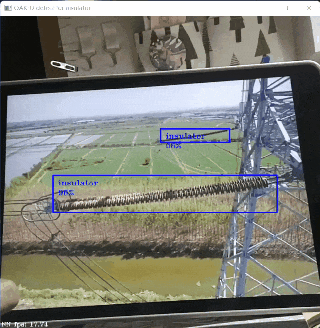
训练好模型之后,就会得到 .pth 格式的权重文件(格式可转化为 .onnx 格式,后文会介绍),就可以用它来预测图片了,我的预测结果如本博客开头所示。
与默认结果稍有不同的是,我调用了目标预测的计数值,通过 PIL 库的 ImageDraw 模块将其显示在了图片右下角,以实现绝缘子数量的统计。
引入 CBAM 注意力机制
为了有一些创新性,我参考 YOLOX引入注意力机制_你的陈某某_CSDN 引入了 CBAM 注意力机制。
引入 CBAM 后,要重新训练模型得到权重文件,预测时也要用插入 CBAM 后的 YOLO 网络。
简单来讲,注意力机制就是让神经网络更多地关注关键信息,忽略次要信息。
示意图(引用自 CBAM 论文原文)
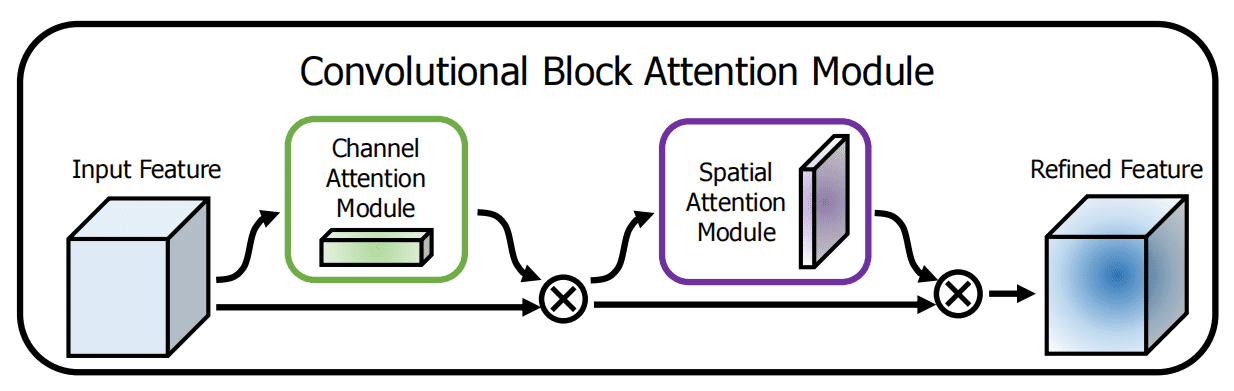
图中的 Refined Feature 相较于原始的 Input Feature,更集中地包含了检测目标的关键信息,使得模型的性能有所提高。
直观一点的解释,如下图所示,分别是插入 CBAM 前后预测结果的 heatmap:

可以看出,引入 CBAM 后,特征区域覆盖到了绝缘子的更多部位,说明 CBAM 确实起到了让神经网络更多地关注关键信息的效果。
在性能指标上也有一定的体现,引入 CBAM 前后的 F1 曲线如图所示:
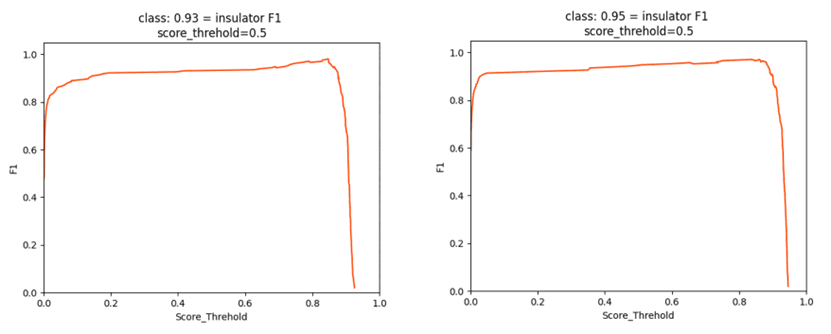
提升比较细微,这与数据集本身、CBAM 插入的位置等因素有关。
OAK-D 实验研究
这个东西就是 OAK-D:

别看它看上去就像个摄像头,但它可比摄像头厉害多了 首先在价格上就贵了 10 倍,二者的主要区别是在软件层面。
普通的摄像头就是一个输入设备,只具有捕捉外部图像的基本功能。摄像头采集图像后,由感光组件等控制电路对图像进行处理,转换为数字信号,然后通过 USB 端口输入给电脑上,供其识别处理。
OAK-D 的核心不是感光组件电路什么的,而是视觉处理单元 VPU。OAK-D 围绕 VPU 聚合了各种强大的软件算法,如人工智能推理加速、深度立体视觉、3D 神经网络推理、OpenCV 图像处理等。因而它有着丰富的 API 接口,通过 官方文档 提供的函数调用即可,YOLO 就是其封装好的算法之一。
简单来讲,如果你哪天手头里有训练好的权重文件、一个普通摄像头和一个 OAK-D,却没有 YOLO 网络的代码,那么你的摄像头就用不了这个权重文件来预测。而只要记得 OAK-D 的 API 函数名,就能用权重文件来预测(假设已有 OAK-D 的启动逻辑代码)。
一开始我是尝试能不能用 YOLOX 训练的模型转化为 OAK-D 能用的格式,先转化为 .onnx 格式,又转化为 .blob 格式,再通过官方提供的 demo 调用,发现行不通,提示的错误信息也千奇百怪。
因为我对涉及的知识了解得不够细致,如 .onnx 格式、.blob 格式、OAK-D 的节点逻辑等,所以我也不晓得咋进一步修改。
后来按照官方提供的 Yolov5 6.0 转换成blob格式,用 YOLOv5 重新训练了一个 .pt 格式的权重文件,按其教程先转化为 .onnx 通用格式,通过 Netron 将其可视化,在最后一层添加 3 个 sigmoid 层,如图所示:
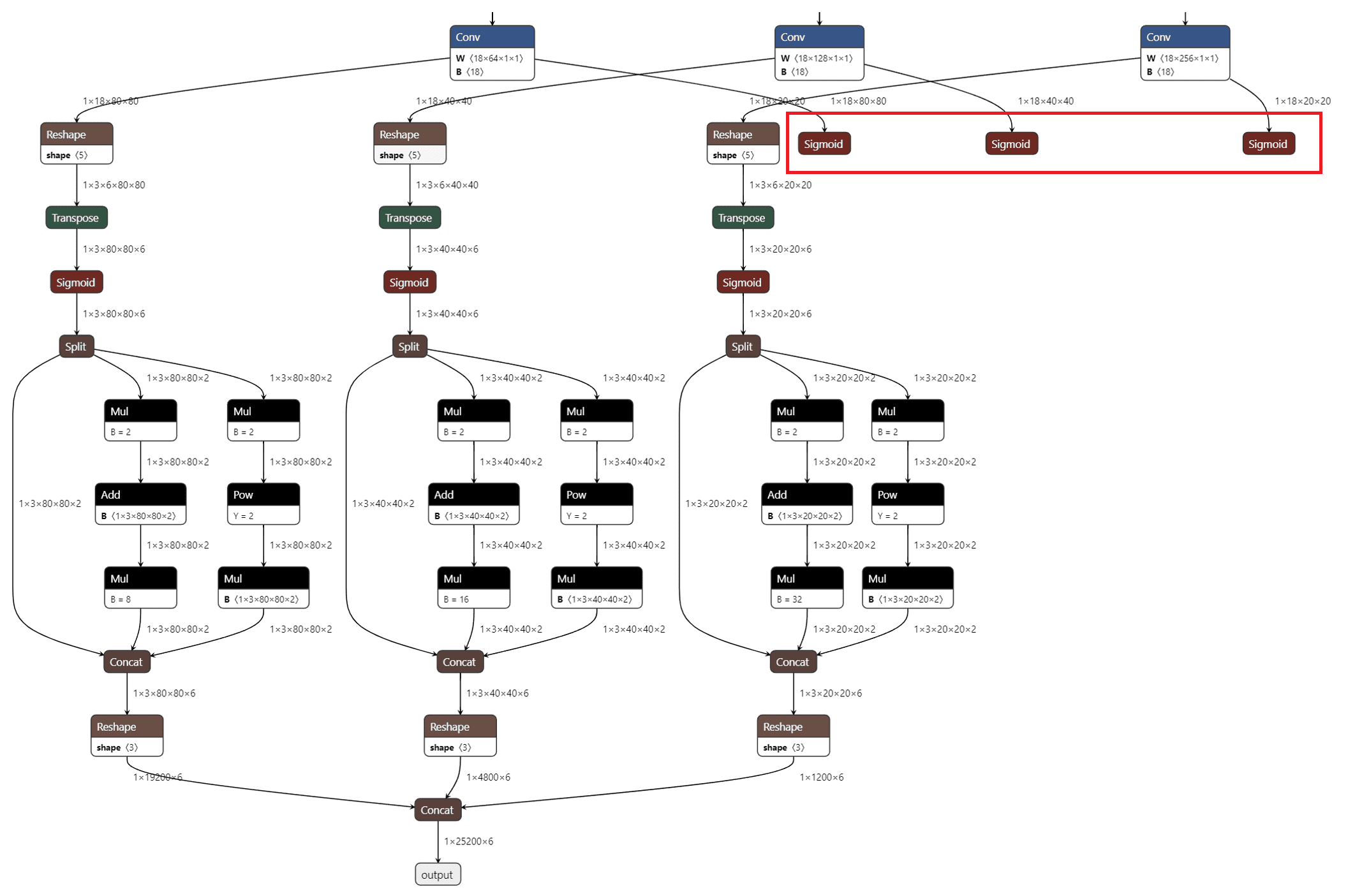
添加完 sigmoid 层之后再修转化为 .blob 格式,最后在官方的 Tiny YOLO demo 基础上修改锚框(Anchor)信息、窗口大小(camRgb.setPreviewSize(640, 640))、预测类别个数等细节即可。
总结
总结
本文的成果可以进一步封装为简洁的软件形式,如 YOLOv5检测界面-PyQt5实现,实现一键训练、一键识别等。
机器视觉的最终目标是与人类的神经视觉网络相媲美,相信那一天在不远的将来。